Anomalous Human Activity Detection
Abstract
Anomaly detection refers to identifying behavior in data that is different from normal. This can range from detecting malicious activity in a video to detecting earthquakes in seismic data. Anomaly detection methods based on convolutional neural networks (CNNs) typically leverage proxy tasks, such as reconstructing input video frames, to learn models describing normality without seeing anomalous samples at training time, and quantify the extent of abnormalities using the explicit reconstruction error at test time. The main drawbacks of these approaches are that they do not consider the diversity of normal patterns. Also, many existing approaches require many normal samples from a particular scene before they can detect anomalies. This makes deployment in the real-world impractical. This report will look at an approach that tackles both issues. We will also look at the detail code, which can enable any anomaly detection model to be adapted for a new scene using a few frames. The code is available on GitHub.
BackGround
Anomaly Detection For Humans
The activities of a human being can be broadly classified into normal or abnormal activities. A human being’s deviation from expected behavior causing harm to the surroundings or himself is categorized as an abnormal activity. The extensive research of human activity recognition and its applications has thrown light upon anomaly detection. The existing approaches for anomalous human activity recognition are built based on the type and speed of object movements and how the objects of interest interact.
It is extensively used for the prediction of time series data in which certain regularities are checked in the data dimension. This can be used to predict stock market prices, weather forecasting, and time series prediction. It is also applied in the area of surveillance. This involves identifying abnormal activities in videos which otherwise is heavily dependent on manual monitoring and is, therefore, both human resource-intensive and time-consuming. Some existing approaches to go about this task include learning the latent space representation corresponding to normal activities.
Memory Networks
There are several attempts to capture long-term dependencies in sequential data. Long short-term memory (LSTM) addresses this problem using local memory cells, where hidden states of the network record information in the past partially. The memorization performance is, however, limited, as the cell size is typically small, and the knowledge in the hidden state is compressed. To overcome the limitation, memory networks have recently been introduced. It uses a global memory that can be read and written to and performs a memorization task better than classical approaches. The memory networks, however, require layer-wise supervision to learn models, making it hard to train them using standard backpropagation. More recent works use continuous memory representations or key-value pairs to read/write memories, allowing us to train the memory networks end-to-end. Several works adopt the memory networks for computer vision tasks, including visual question answering, one-shot learning, image generation, and video summarization. We would also discuss a memory module for anomaly detection with a different memory updating strategy, which records patterns of normal data to individual items in the memory and considers each item as a prototypical feature.
Prototypes and Criticisms
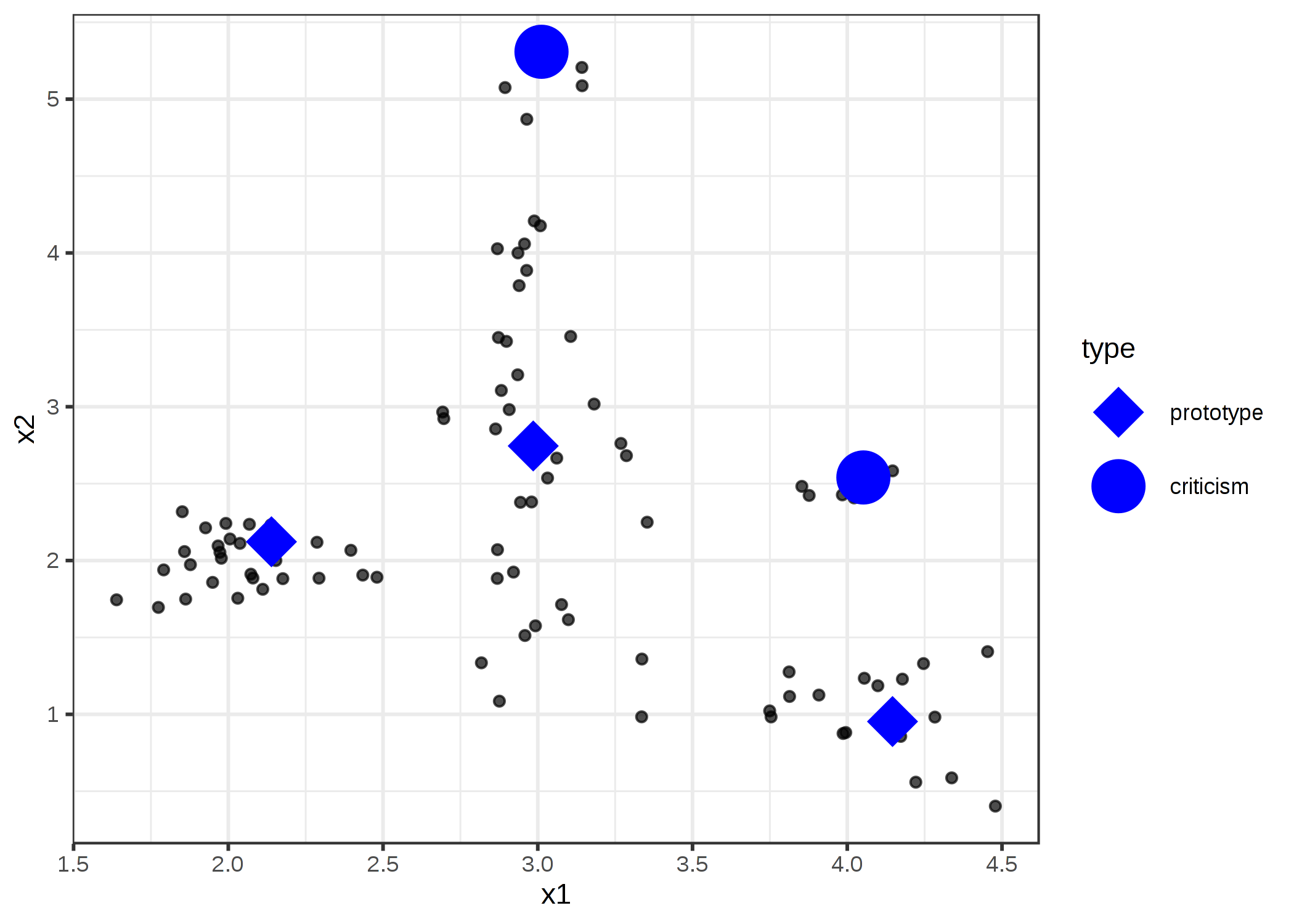 A prototype is a data instance that is representative of all the data. A criticism is a data instance that is not well represented by the set of prototypes. The purpose of criticisms is to provide insights together with prototypes, especially for data points which the prototypes do not represent well. Prototypes and criticisms can be used independently from a machine learning model to describe the data, but they can also be used to create an interpretable model or to make a black box model interpretable.
A prototype is a data instance that is representative of all the data. A criticism is a data instance that is not well represented by the set of prototypes. The purpose of criticisms is to provide insights together with prototypes, especially for data points which the prototypes do not represent well. Prototypes and criticisms can be used independently from a machine learning model to describe the data, but they can also be used to create an interpretable model or to make a black box model interpretable.
The expression “data point” is used to refer to a single instance, to emphasize the interpretation that an instance is also a point in a coordinate system where each feature is a dimension. The following figure shows a simulated data distribution, with some of the instances chosen as prototypes and some as criticisms. The small points are the data, the large points the criticisms and the large squares the prototypes. The prototypes are selected to cover the centers of the data distribution and the criticisms are points in a cluster without a prototype.
Our approach and Results
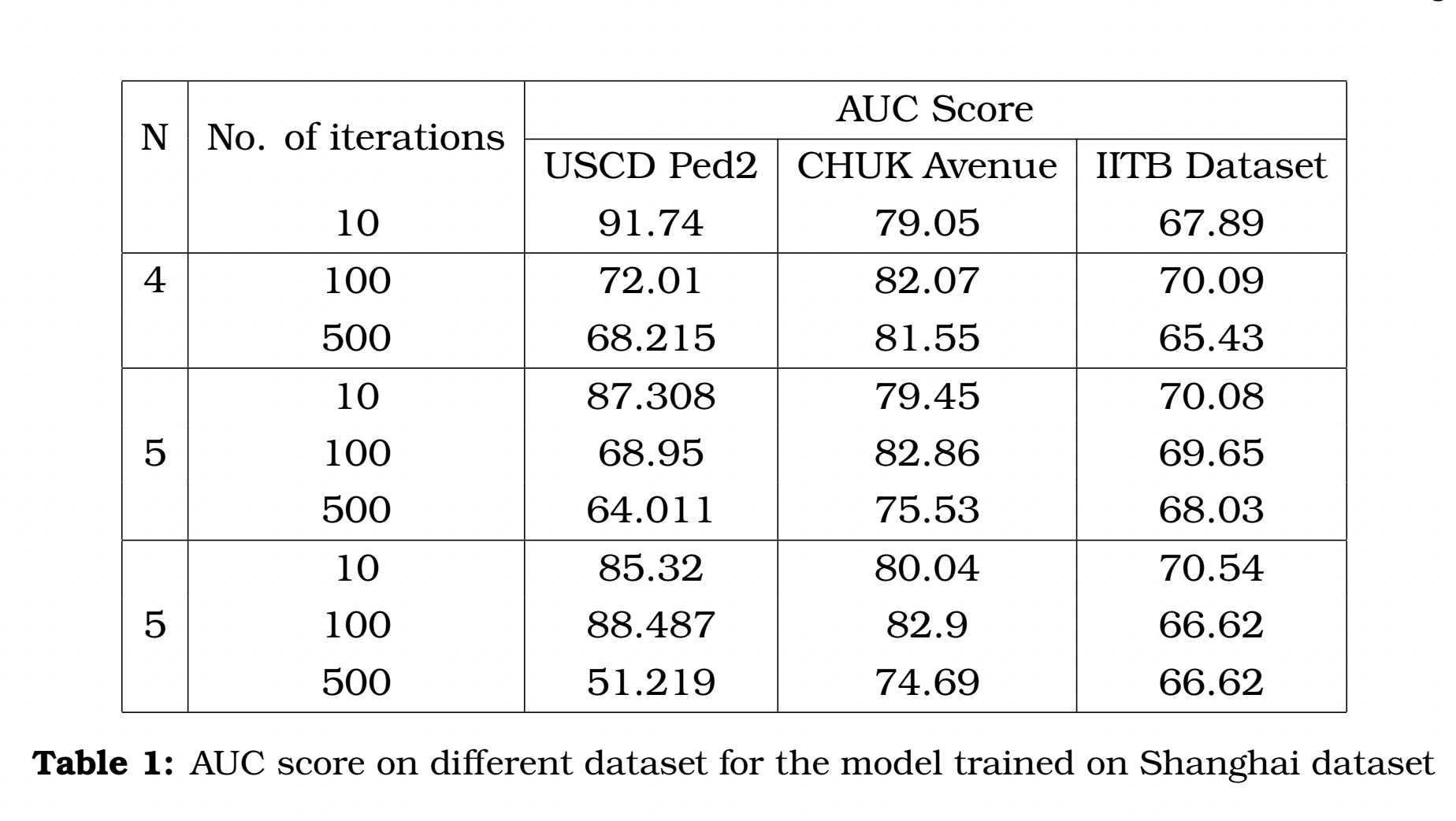
We used the Meta-Training process laid out in the above to train the prototypical memory model for anomaly detection. Hence hoping to achieve the benefits of the prototypical model using only few frames, and hence cane be used to deploy in real life. Here are some of the results we achieve using this approach on different datasets.